A tale of debugging - the LinkedIn API, .NET and HTTP protocol violations
In my last project, I was in charge of integrating the LinkedIn API into .NET 4 application. A few weeks after launch and during a client demo (of course), a request to the LinkedIn API failed with the following cryptic WebException:
The server committed a protocol violation. Section=ResponseHeader Detail=CR must be followed by LF
We had thouroughly tested the LinkedIn API over several months before launch, had a dedicated team of testers and had a full suite of automated integration tests against the API, yet had never seens this error before. In fact, I'd never seen this error before in my life - and I've implemented my fair share of third-party REST API integrations.
Since we were investigating another issue at the time, we put that one down on a temporary network glitch and moved on...
...until both our QA team and our automated tests were able to consistently reproduce the issue the following morning. A few informal tests later and it was looking like 10% of POST HTTP requests to a key (for us) endpoint of the LinkedIn API were failing with this error. We had a problem.
Step 1: Google
Although no-one seemed to have encountered this issue in relation to the LinkedIn API, I did find quite a few reports of this error occuring when trying to access various HTTP endpoints using .NET's HttpWebRequest class.
The solution always given was to add the useUnsafeHeaderParsing flag to the application's configuration file.
As both its name and documentation indicate, you really shouldn't use this flag. Use it only as a last-resort workaround when all else failed. Even then, and especially since this flag can only be applied at the application-level and will affect all HTTP requests made by the application, you should consider whether you could just stop making the problematic HTTP requests rather than applying this flag.
Rather worryingly, it seems that many developers faced with this issue are just accepting this flag as being the "solution" and apply it without thinking twice about it. Accepting invalid external data into your application is always a gapping security hole waiting to be exploited. Don't do that.
At a push and if the problem has a significant business impact, you could consider applying this flag as a temporary workaround until you find the root of the problem (but keep reading for a much safer potential workaround). In our case, the answer of our DevOps team to the suggestion of enabling this flag as a temporary stop-gap in production was a big fat: NO.
The problem
With no known solution, time to dig into the actual problem.
The exception message points to a problem with the HTTP headers in the response sent by the LinkedIn API. At the time, the HTTP protocol was defined in RFC 2616 (in June 2014, RFC 2616 was deprecated in favour of new RFCs 7230, 7231, 7232, 7233, 7234 and 7235).
Section 2.2 of RFC 2616 states it clearly:
HTTP/1.1 defines the sequence CR LF as the end-of-line marker for all protocol elements except the entity-body.
Section 4.1 documenting the format of HTTP messages reiterates:
generic-message = start-line
*(message-header CRLF)
CRLF
[ message-body ]
start-line = Request-Line | Status-Line
So here it is: every HTTP header must be terminated by a CRLF (\r\n) sequence.
If the exception message was correct, it looked like the LinkedIn API was sometimes ommitting the LF character (as we'll see later, the exception message was wrong in this instance. The problematic responses were in fact ommitting the CR character).
It should be noted that section 19.3 of RFC 2616 does advise that tolerant applications can accept HTTP headers that are terminated by a LF character only instead of a CRLF sequence. Section 3.5 of RFC 7230, which replaces and deprecates RFC 2616, makes a similar provision:
Although the line terminator for the start-line and header fields is
the sequence CRLF, a recipient MAY recognize a single LF as a line
terminator and ignore any preceding CR.
HTTP header parsing in .NET
So how does .NET's HttpWebRequest class implement this recommendation? The answer lies in the Connection.ParseResponseData() method:
private DataParseStatus ParseResponseData([...])
{
[...]
switch (m_ReadState) {
[...]
case ReadState.Headers:
[...]
if (SettingsSectionInternal.Section.UseUnsafeHeaderParsing)
{
parseSubStatus = m_ResponseData.m_ResponseHeaders.ParseHeaders([...]);
}
else
{
parseSubStatus = m_ResponseData.m_ResponseHeaders.ParseHeadersStrict([...]);
}
[...]
}
[...]
}
If the useUnsafeHeaderParsing flag isn't set in your application configuration file (and it isn't by default), HTTP headers are parsed with the WebHeaderCollection.ParseHeadersStrict() method. As its name suggests, this method doesn't tolerate any deviation from the standard:
internal unsafe DataParseStatus ParseHeadersStrict([...])
{
[...]
fixed (byte* byteBuffer = buffer)
{
while (true)
{
// If this is CRLF, actually we're done.
if (byteBuffer[i] == '\r')
{
if (byteBuffer[i++] == '\n')
{
totalResponseHeadersLength += i - unparsed;
unparsed = i;
parseStatus = DataParseStatus.Done;
goto quit;
}
parseStatus = DataParseStatus.Invalid;
parseErrorCode = WebParseErrorCode.CrLfError;
goto quit;
}
[...]
}
[..]
}
[...]
}
At soon as it comes accross a CR not followed by a LF, it exits early with the error that gets eventually thrown as a WebException.
That takes care of one side of the equation. But what about an LF not preceed with a CR, which is the specific case RFCs 2616 and 7230 mention? This case is handled later on in that same method:
int crlf = 0; // 1 = cr, 2 = crlf
for ([...])
{
switch (ch)
{
case RfcChar.WS:
if (crlf == 1)
{
break;
}
crlf = 0;
continue;
case RfcChar.CR:
if (crlf == 0)
{
crlf = 1;
continue;
}
break;
case RfcChar.LF:
if (crlf == 1)
{
crlf = 2;
continue;
}
break;
}
parseStatus = DataParseStatus.Invalid;
parseErrorCode = WebParseErrorCode.CrLfError;
goto quit;
}
If an LF not preceeded with a CR is found, exit early.... with an incorrect error message
So if you get a WebException with a message of "The server committed a protocol violation. Section=ResponseHeader Detail=CR must be followed by LF", it could mean that there was a missing LF as indicated in the error message. But it could also mean that the missing character is in fact the CR.
The WebHeaderCollection.ParseHeaders() method on the other side happily accepts a lone LF as a terminator for an HTTP header as suggested for a tolerant client by the RFCs.
Unfortunately, as you can see here, the only way to trigger this lenient parsing is to set the useUnsafeHeaderParsing flag, which:
- Can only be applied at the application level - it cannot be set for a set for a specific request only.
- Disables a number of different validations - not just the check for the CRLF termination sequence. It's not possible to selectively disable the CRLF check only.
HttpWebRequest can only be praised for being strict by default when parsing HTTP messages. But only providing an application-level flag for relaxing the parsing rules is a pretty big oversight on the part of .NET's designers.
Reproducing the issue
With a pretty good idea of where the error was coming from, I now needed some more hard data before I could file a report with LinkedIn. In particuar, I had to rule out the issue being caused by a bug in our stack. I also had to verify that our assumption about the root cause of the problem was correct by gathering some raw header data we could examine.
So I put together a small console app that used HttpWebRequest to make 50 POST requests to the problematic HTTP endpoint and report the number of calls that failed. You can find the code on GitHub.
I ran the app and... all the requests succeeded. I couldn't reproduce the issue. Maybe the issue had somhow been fixed in the time it took me to write this app?
I re-ran our LinkedIn API integration tests. 10% of all POST requests failed with an HTTP protocol violation error. The issue had clearly not been fixed. Maybe the bug was on our side after all...
Time to dig deeper in our code base. Our API wrapper was based on RestSharp. A look at RestSharp's Http class where the HttpWebRequest is created and configured revealed an interesting twist:
private HttpWebRequest ConfigureWebRequest(string method, Uri url)
{
var webRequest = (HttpWebRequest)WebRequest.Create(url);
webRequest.PreAuthenticate = PreAuthenticate;
ServicePointManager.Expect100Continue = false;
// [...]
}
So RestSharp always disables HTTP 100 Continue, which is enabled by default for all POST requests made with the HttpWebRequest class.
Incidently, it makes sense for a REST client to disable this behaviour as POST request bodies will always be small when working with a REST API. The '100 Continue' flow would do nothing in this case but introduce a completely uncessary delay in all POST requests.
As an aside, the way RestSharp disables the '100 Continue' behaviour could be considered as a bug. Instead of disabling it at the request level as it should be, it disables it on the singleton ServicePointManager, which results in '100 Continue' being disabled for all HttpWebRequest created from that point onwards in the current App Domain. I'll submit a pull request to get this fixed.
Back to your debugging journey: I disabled 100 Continue in my test console app and, low and behold, 10% of the requests failed with an HTTP protocol violation error. So enabling '100 Continue' appeared to be a workaround.
How does '100 Continue' relate the the HTTP header termination sequence?
It doesn't. They're completely unrelated.
My only guess for '100 Continue' fixing the HTTP protocol violation error we were having is that enabling it perhaps caused our request to get routed to a different server within LinkedIn's server pool. A server that wasn't buggy. Or perhaps, it caused a different code path to be taken, working around the buggy part.
In any case, while enabling '100 Continue' appeared to be a workaround for the issue (at least at that time), it didn't fix the cause of the problem.
Inspecting raw HTTP headers. Attempt #1: retrieving the response data from the WebException
Now that we could easily and consistently reproduce the problem, time to take a look at those supposedly invalid HTTP headers.
My first guess was to inspect the WebException that was getting thrown when HTTP header parsing failed due to the protocol violation. With a bit of luck, it would include a snippet of the problematic data.
No such luck however. Although WebException has a Response property, which contains the HttpWebResponse that caused the error, this is only set when the full HTTP message parsing was successful. In our case, since HttpWebRequest failed to even parse the HTTP headers, WebException.Response was left null. I was hoping that the exception would including some of the raw socket data somewhere but WebException contains nothing of the like.
Going through the HTTP header parsing source code in the WebHeaderCollection.ParseHeadersStrict() method shows that there is no hidden trick that will let you access the raw data after the fact: the raw data isn't stored anywhere and is immediately discarded after being parsed.
Inspecting raw HTTP headers. Attempt #2: Fiddler
If the raw data we need isn't made available to us from within our application, we'll have to capture it on the wire before is reaches our application. The first tool that comes in mind to do this is Telerik's Fiddler.
No introduction or guide is necessary there I guess - there's nothing easier to use than Fiddler.
Using Fiddler seemed to be our best bet in this situation as the LinkedIn API uses OAuth 2.0 and is therefere only accessible via HTTPS. In order to inspect the HTTP headers, we therefore needed to not only intercept the network traffic but also decrypt the HTTPS data. As it happens, one of Fiddler's best feature is its ability to transparently decrypt and display HTTPS traffic coming from any process on your local machine at the tick of a check box. It does this by creating its own root CA and configuring Windows to trust it. It can then insert itself into an HTTPS conversation and generate an appropriate certificate on-the-fly using its root CA.
So I fired up Fiddler and attempted to reproduce the issue. Try as you might, I couldn't. It seemed that when running the networking traffic through Fidler's proxy, the issue just went away.
There's not an awful lot of information on how Fiddler works under the hood. It's also not open source. From what I could gather and observe however, it is certain that Fiddler's proxy isn't quite as transparent as you might expect. It definitely does some massaging of the data. The data your application receives when running through Fiddler might have been tampered with by Fiddler. In our case, Fiddler was automatically fixing up the HTTP headers behind our back, making it useless for our purpose.
The Raw view in Fiddler also doesn't appear to display the actual raw data read from the socket. Some data massaging appears to be applied there as well, including fixing up line endings.
Inspecting raw HTTP headers. Attempt #3: .NET's network tracing feature
.NET has a (perhaps) little-known but very handy network tracing feature. Enabling it couldn't be it easier - just add the following system.diagnostics section to your web.config or app.config file:
<configuration>
<system.diagnostics>
<sources>
<source name="System.Net">
<listeners>
<add name="System.Net"/>
</listeners>
</source>
<source name="System.Net.Http">
<listeners>
<add name="System.Net "/>
</listeners>
</source>
<source name="System.Net.Sockets">
<listeners>
<add name="System.Net"/>
</listeners>
</source>
</sources>
<switches>
<add name="System.Net" value="Verbose"/>
<add name="System.Net.Http" value="Verbose"/>
<add name="System.Net.Sockets" value="Verbose"/>
</switches>
<sharedListeners>
<add name="System.Net" type="System.Diagnostics.TextWriterTraceListener" initializeData="network.log"
/>
</sharedListeners>
<trace autoflush="true"/>
</system.diagnostics>
</configuration>
(here only including the traces we're interested in. Refer to the documentation for all the possible values).
The resulting trace is written to whatever trace listener you've configured - here in a file called network.log.
Running our test app making POST requests to the problematic HTTPS endpoint with network tracing enabled resulted in a network trace which contained all the raw socket data we nedeed... but encrypted of course. Not of very much use.
At this point, I decided to try and make the problematic POST queries over HTTP instead of HTTPS. Of course, the LinkedIn API doesn't allow the use of HTTP when using OAuth 2.0 authentication so it always returns a 401 in that case. But I was wondering if the issue would still happen then.
And it did. Just like when POSTing over HTTPS, posting over HTTP resulted in 10% of the requests failing with an HTTP protocol violation error.
We were back in business. Re-running the test app reconfigured to make requests over HTTP with network tracing enabled resulted in much more useful data:
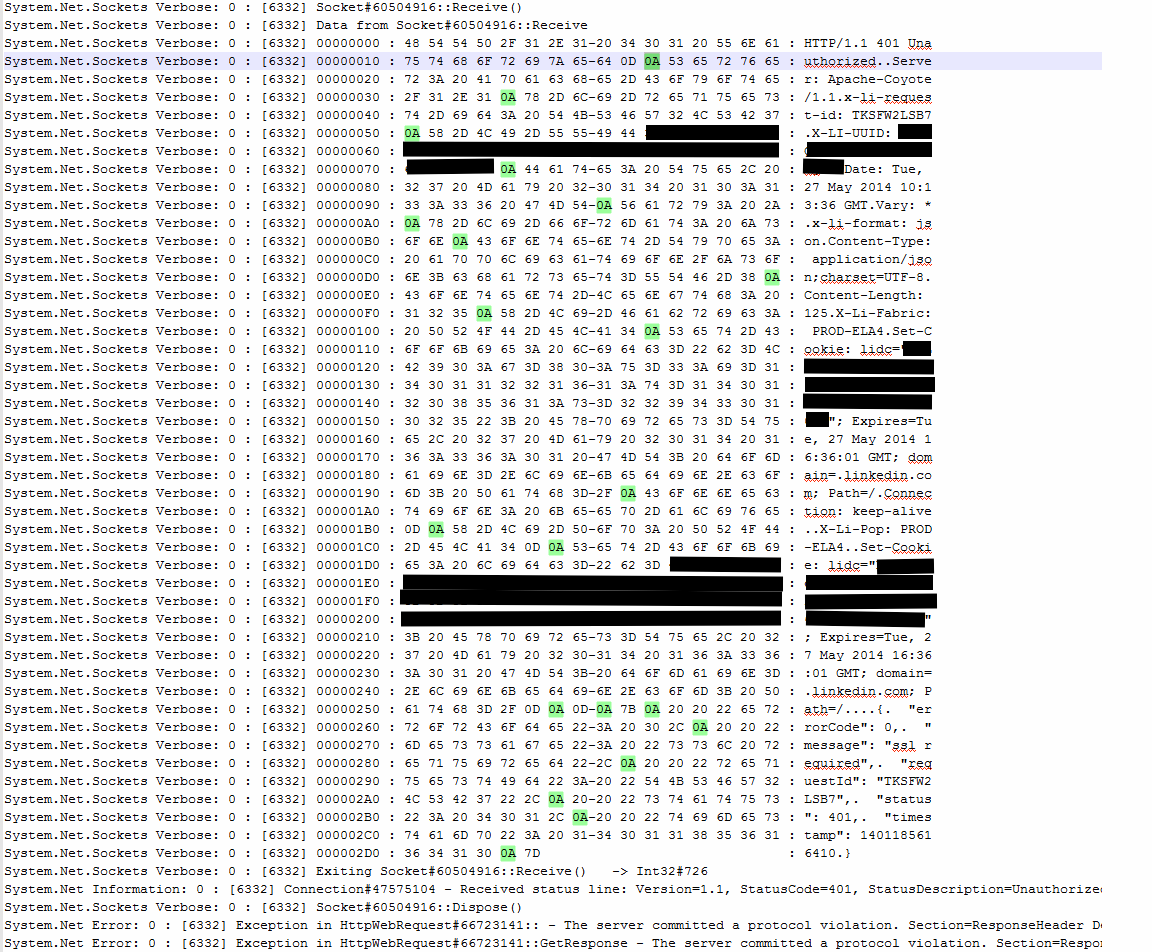
The problem is finally here in plain sight: several of the HTTP headers in the response sent by the LinkedIn API are terminated with a lone LF character (0x0A) instead of a CRLF sequence (0x0D 0x0A).
Inspecting raw HTTP headers. Attempt #4: Wireshark
We now had hard data establishing that some of the responses sent by LinkedIn were not well formed. But I was curious to see if the IP and TCP headers of the malformed packets would reveal any more useful information.
Enter Wireshark.
Just like Fiddler, there's not much to say about Wireshark - it just works. When viewing a capture, right-click a network packet and you'll find some handy pre-built "conversation filters" that let you follow a network conversation by IP address or TCP stream.
In our case, applying the following filter when viewing a capture filters out all but the relevant packets: HTTP responses coming from the problematic server:
ip.addr eq 216.52.242.83 and http.response
And this is what it looks like:
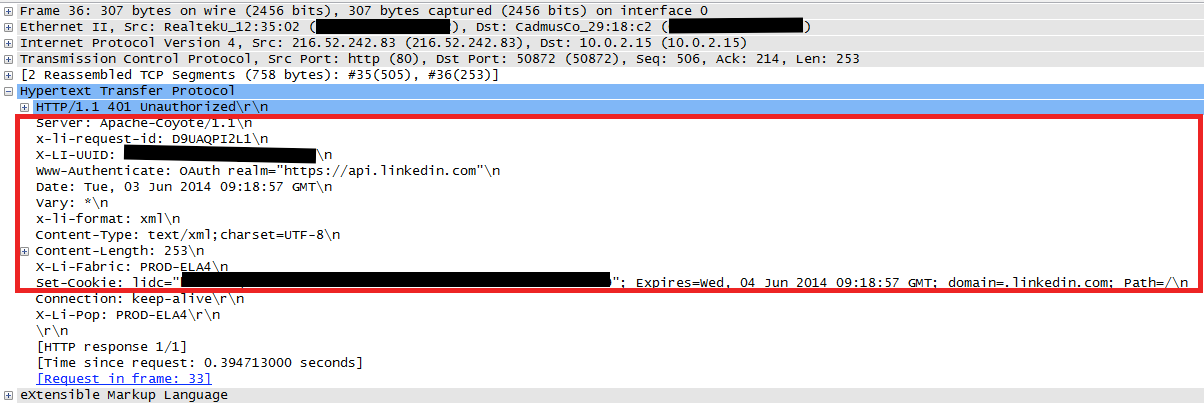
The IP and TCP headers didn't reveal anything interesting. But Wireshark's UI makes it a lot easier to analyses raw response data. The malformed HTTP headers are clearly visible here.
And being able to quickly scan through a list of well-formed and malformed reponse headers allowed me to spot a few more oddities in the headers presents in the malformed response, which may have helped LinkedIn's team to isolate and fix the problem more quickly.
Beware when sending a Wireshark capture file to a third party that it captures all the network traffic going through your local machine by default. And that will most likely include some sensitive information. When running a Wireshark capture with the intention of sending it to a third-party, you might want to use the following capture filter to only capture the relevant data:
host 216.52.242.83
(of course replace with IP with the address whatever remote server you're troubleshooting)
Replicating the issue with Python
Last but not least, since LinkedIn is a Java / Scala / Python shop and probably wouldn't be able to run my .NET test application, I put together a quick Python script to replicate the issue so that they could replicate it themselves. The code is on GitHub if you're interested.
Unfortunately, Python happily accepted the malformed HTTP responses. There seemed to be no way to reproduce the issue with Python.
So what was happening there?
In Python, regardless of whether you use httplib, httplib2, urllib, urllib2 or requests to make your web request (who said there's only one way to do it in Python?), the request will eventually be created and executed within httplib.
httplib is open-source. The HTTP parsing code can be found in the HTTPMessage.readheaders method. Each HTTP header is read with:
line = self.fp.readline(_MAXLINE + 1)
Looks fishy. How does that readline method deal with line ending?
The mysterious fp member variable is created earlier on in HTTPResponse.__init__:
if buffering:
# The caller won't be using any sock.recv() calls, so buffering
# is fine and recommended for performance.
self.fp = sock.makefile('rb')
else:
# The buffer size is specified as zero, because the headers of
# the response are read with readline(). If the reads were
# buffered the readline() calls could consume some of the
# response, which make be read via a recv() on the underlying
# socket.
self.fp = sock.makefile('rb', 0)
The documentation for socket's makefile clarifies it:
Return a file object associated with the socket.
So fp is an object that exposes a file-like interface on top of a socket.
How is it implemented? This is the source code for socket.py. And this is what makefile does:
def makefile(self, mode="r", buffering=None, *, encoding=None, errors=None, newline=None):
[...]
raw = SocketIO(self, rawmode)
[...]
buffer = io.BufferedReader(raw, buffering)
[...]
text = io.TextIOWrapper(buffer, encoding, errors, newline)
text.mode = mode
return text
So our fp is an io.TextIOWrapper that reads from the socket. And the newline parameter is set to None.
What does the documentation for io.TextIOWrapper tells us about this?
On input, if newline is None, universal newlines mode is enabled. Lines in the input can end in '\n', '\r', or '\r\n', and these are translated into '\n' before being returned to the caller.
The glossary for universal newline mode doesn't leave any room for ambiguity either:
universal newlines: A manner of interpreting text streams in which all of the following are recognized as ending a line: the Unix end-of-line convention '\n', the Windows convention '\r\n', and the old Macintosh convention '\r'.
So that explains it. It's not that Python is being intentionally lenient when parsing HTTP headers. It's that it doesn't make any attempt to implement the HTTP protocol properly...
Replicating the issue with Go
With Python a no-go, I then tried to replicate the issue with Go. The code is on GitHub.
Just like with Python, I couldn't replicate the issue with Go. Time to digg deeper. Again.
This is Go's source code. Which is incidently refreshingly clean and easy to read compared to that of the .NET Framework or Python (but then you would expect as much from a modern, two year old language).
The parsing of HTTP headers is kicked off in the ReadResponse() method defined in the net/http/response.go file:
func ReadResponse(r *bufio.Reader, req *Request) (*Response, error) {
tp := textproto.NewReader(r)
resp := &Response{
Request: req,
}
[...]
// Parse the response headers.
mimeHeader, err := tp.ReadMIMEHeader()
if err != nil {
if err == io.EOF {
err = io.ErrUnexpectedEOF
}
return nil, err
}
resp.Header = Header(mimeHeader)
[...]
}
So Go creates a new Reader defined in the textproto package and uses it to parse the headers. The textproto.NewReader() method is defined in the net/textxtproto/reader.go file.
You'll see there that Go adopts an HTTP parsing approach somewhat similar to that of Python by creating an abstraction over the socket's byte stream that allows it to read the data on a line-by-line basis. It however differs from Python's approach in that the abstraction it uses is specialized to read text-based network protocols. Go doesn't try to pretend that it's just reading a text file. Which means that the textproto.Reader class can handle all the peculiarities of network protocols.
So what's happening in the ReadMIMEHeader() method?
func (r *Reader) ReadMIMEHeader() (MIMEHeader, error) {
// Avoid lots of small slice allocations later by allocating one
// large one ahead of time which we'll cut up into smaller
// slices. If this isn't big enough later, we allocate small ones.
var strs []string
hint := r.upcomingHeaderNewlines()
if hint > 0 {
strs = make([]string, hint)
}
m := make(MIMEHeader, hint)
for {
kv, err := r.readContinuedLineSlice()
if len(kv) == 0 {
return m, err
}
[...] // Parse kv as a Key / Value header
}
}
The key method here is readContinuedLineSlice() which reads and returns a single HTTP header.
This method implements HTTP's line folding mechanism defined in section 4.2 of RFC 2616 whereby an HTTP header can span accross multiple lines by prefixing each additional line by one of more white space character (this provision has since been deprecated in section 3.2.4 of RFC 7230 - HTTP headers are not allowed to span accross multiple lines anymore):
func (r *Reader) readContinuedLineSlice() ([]byte, error) {
// Read the first line.
line, err := r.readLineSlice()
if err != nil {
return nil, err
}
if len(line) == 0 { // blank line - no continuation
return line, nil
}
// Optimistically assume that we have started to buffer the next line
// and it starts with an ASCII letter (the next header key), so we can
// avoid copying that buffered data around in memory and skipping over
// non-existent whitespace.
if r.R.Buffered() > 1 {
peek, err := r.R.Peek(1)
if err == nil && isASCIILetter(peek[0]) {
return trim(line), nil
}
}
// ReadByte or the next readLineSlice will flush the read buffer;
// copy the slice into buf.
r.buf = append(r.buf[:0], trim(line)...)
// Read continuation lines.
for r.skipSpace() > 0 {
line, err := r.readLineSlice()
if err != nil {
break
}
r.buf = append(r.buf, ' ')
r.buf = append(r.buf, line...)
}
return r.buf, nil
}
Which brings us to the readLineSlice() method:
func (r *Reader) readLineSlice() ([]byte, error) {
r.closeDot()
var line []byte
for {
l, more, err := r.R.ReadLine()
if err != nil {
return nil, err
}
// Avoid the copy if the first call produced a full line.
if line == nil && !more {
return l, nil
}
line = append(line, l...)
if !more {
break
}
}
return line, nil
}
We're now close to the finish line. The line is read by the ReadLine() method of the R property of the Reader class. R turns out to be a bufio.Reader:
type Reader struct {
R *bufio.Reader
dot *dotReader
buf []byte // a re-usable buffer for readContinuedLineSlice
}
bufio.Reader is defined in the bufio/bufio.go file. And its implementation is what you expect:
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error) {
line, err = b.ReadSlice('\n')
[...]
}
There we have it. Just like Python, Go isn't being intentionally lenient what parsing HTTP headers. It instead doesn't even try to verify that they comply with the standard and it accepts a single LF character as a valid termination sequence for an HTTP header.
Epilogue
Playing around some more, I noticed that the issue didn't just happen with the specific API endpoint we were using. It happened for all POST data to that server, even when making requests to non-existing endpoints. It also didn't seem application server-related as both endpoints served with Apache Tomcat and with lighthttpd were affected.
Armed with this additional bit of information and with our Wireshark captures, we were able to file a detailled report with LinkedIn. Within a few hours, their SRE team had fixed the issue.
In closing - troubleshooting "The server committed a protocol violation" errors in .NET
If you get a WebException with the following message:
The server committed a protocol violation. Section=ResponseHeader Detail=CR must be followed by LF
...when executing an HTTP request via HttpWebRequest (or a wrapper library such as RestSharp), here are a few tips for troubleshooting it:
-
Replicate the issue with a minimal program. You can use this one as a template.
-
If the issue happens on an HTTPS endpoint, see if you can replicate it over HTTP as well (even if that endpoint doesn't normally allow HTTP requests). Otherwise, you'll have trouble inspecting the malformed responses.
-
Establish the scope of the issue. E.g. does this issue happen for a specific endpoint only or for any request to a specific server?
-
Use Wireshark to capture the network traffic and inspect the raw response data. Refer to the Wireshark section above for some tips. You should be able to pinpoint the issue. You can refer to RFC 7230 for a refresher on the HTTP message format if needed.
-
If the problem only occurs over HTTPS you'll only see encrypted data, which won't be of any use. Note that Fiddler probably won't be of any use either here (see the Fiddler section above for the reason why). In that case, you might want to look at enabling HTTPS decrytion in Wireshark - I haven't tried this yet.
-
Contact the administrator of the faulty server with the Wireshark data. They should hopefully be able to fix the issue.
Note that you might not be able to replicate the issue with other languages. See the Python and Go sections above for examples of how other languages and networking libraries differ from .NET's implementation.
Workarounds
If you can't get the admin of the problematic server to fix the issue, your options are limited. Take your pick:
Option 1: Don't use that HTTP endpoint. Find an alternative. If a server returns non-standard-compliant data and its admin is unwilling to fix it, you're better off staying well clear from it.
Option 2: If the problem only affects POST requests, see if enabling the '100 Continue' flow on those requests would fix the issue by any chance:
var request = WebRequest.Create(url) as HttpWebRequest;
request.ServicePoint.Expect100Continue = true;
While there is technically speaking no relation between the '100 Continue' flow and the HTTP header termination sequence, I've found at least one situation when enabling '100 Continue' somehow caused the request to work around the buggy path and therefore "fixed" the HTTP protocol violation issue.
Note that '100 Continue' is enabled by default on HttpWebRequest but may be (mistakenly) disabled at the app domain-level by third party libraries such as RestSharp. It can also be disabled with a configuration setting in your app.config / web.config.
So if you don't control the creation and execution of the HttpWebRequest (because you're using a wrapper of some sort) and therefore can't set its ServicePoint.Expect100Continue value, check your .config file for a servicePointManager section and make sure it's not disabled there. Then check the value of the singleton ServicePointManager.Expect100Continue property. If false, something in your application is disabling the '100 Continue' behaviour at the app domain level. Find out what code is setting that property to false.
Option 3: Finally, if all else failed and you absolutely must access the buggy HTTP endpoint, you can consider applying the useUnsafeHeaderParsing flag in your app.config / web.config. This will fix the issue but will affect all HTTP requests made in the application and will disable a number of other protocol validation rules that may open security holes in your application. It's of course impossible to know how much of an issue not performing these validations is. New exploits are created every day.
Other networking libraries like Python's httplib adopt a much more relaxed and lenient approach to HTTP message parsing, effectively adopting what .NET qualifies as "unsafe header parsing" by default. So if you enable unsafe header parsing and something goes wrong, you'll be able to rely on the good old excuse: "but everyone else was doing it!".